
Planning the Architecture
We previously covered some important team and organizational considerations when preparing for microservices. We’re now going dive into the actual technical planning phases and key considerations for microservice architecture design.
As covered in other great microservice articles, microservice architectures move complexity from internally connected components to the connections between independent services. Building a flexible and performant system requires identifying positive and negative patterns for coupling.
Service Communication
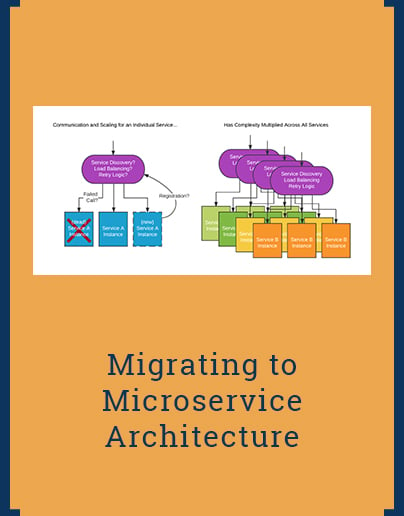
Planning the mechanisms to make Remote Procedure Calls (RPC) between services may appear trivial at first glance. In practice, cross-service communication systems are critical to the architecture and must not be overlooked.
There are three primary questions to consider when selecting your communication stack:
- What protocol transports and formats are you going to support?
- How are service discovery and load balancing applied to service instances?
- What tools and mechanisms for retries and failures need to be supported?
When considering protocols, experts agree that using open protocols which are accessible from a wide variety of languages is important. Also, consider the supporting tools and ecosystems available. Does the tooling include any of the following: Tools for generating or publishing documentation, a UI for making test calls, a tool for mocking the responses, a means of defining and validating request & response schemas, mature model for communicating errors and degraded system states, well documented patterns for extending data structures, sensible data types (e.g. how would you precisely represent money), options for compression or encryption, obvious means to capture and decode traffic for debugging, and standard solutions for routing, load-balancing or proxying requests.
There are countless ways to handle load balancing and service discovery. The protocol options considered inevitably inform the options available. Simple and proven technologies are certainly recommended. Complex or custom solutions could easily cause or compound failures, and make troubleshooting and tuning difficult. Connection pooling and call batching are also worthwhile features to investigate.
Although listed last, handling failures and retries is a significant design decision. Deployments and auto-scaling both require adding and removing instances in predictable ways. Failed calls to dead or dying instances must be seamlessly retried elsewhere. The calls must also be allowed to timeout or be cancelable according to the specific requirements of the callee.

Figure 1: Microservice communication must account for service scaling and availability and be considerate of load-balancing and discovery issues.
Service communication is a complex topic with many considerations. In addition to direct RPC communication, services should also have access to a shared message bus to allow for asynchronous event and data sharing. In addition to the list of service communication requirements above, message buses should be compared on scalability and delivery guarantees. Systems that allow message partitioning per topic, or provide at-least-once delivery, such as Kafka can be incredibly valuable. Take time early in planning to install and do technical shoot-outs with the bus messaging technologies you’re considering. The service bus’s capabilities will dictate the asynchronous patterns available within your architecture.
Think in terms of Capabilities
Services should be designed, implemented, and enhanced based on their designated capabilities. Brainstorm the functionality of current systems, and compare notes with key business divisions. Doing so will allow you to quickly assemble a high-level list of system capabilities. Understanding all required capabilities and how they serve different business groups and customers is critical to segmenting functionality and defining clear boundaries for each microservice.
Defining and grouping capabilities based on data/knowledge domains is an easy starting point. An example of this might be: storing customer data, publishing web content, and tracking customer comments. The groupings identified in this step are then dissected further using an iterative technique. Determine possible service splits within each domain grouping by talking about three areas:
- Consistency and scalability tradeoffs
- Data access patterns
- Codependency of resources or data structures

Figure 2: Traditional systems often contain direct dependencies thru function calling and thru global data schemas. Microservices decouple data and communication to reduce direct dependencies and make them explicit.
Using the example grouping above, the customer data requires strong consistency but lower scalability. The team determines they want an authoritative service for storing customer data, leveraging a dedicated RDBMs. The web publishing system requires higher scalability for published content, so the team considers building two separate services. The first for authoring content, and second optimized for scaling and caching published content. The comments system requires frequent real-time writes, as well as up-vote statistics, but also includes basic poster information, like name and avatar. The team decides to separate this content from the customer and publishing services into its own service using a scalable NoSQL solution. To prevent the comments system from becoming dependent on the customer data service, it will keep its own subset of customer data on-hand. That additional data is kept synchronized by subscribing to customer services updates on the message bus (eventual consistency).
In other circumstances, it will make sense to combine services. As another example, a team has a warehouse management system for tracking inventory and uses enterprise resource planning (ERP) software to set prices. The eCommerce platform frequently needs access to both of these datasets together, and rarely needs them individually. The team decides to build a consolidated service that will intake data feeds from the warehouse and ERP sources and combine them into a single service that can provide data in-bulk for point-in-time levels of price and inventory. This simplifies access for eCommerce applications and provides better scale than directly burdening the warehouse and ERP system.
Consider a Four-Tier Architecture
Separating client code from core service code using APIs is often the initial goal of a microservice architecture. Formalizing that separation further into a four tier architecture can increase the flexibility and performance of a microservice platform.
Core backend services are placed into the services tier. These services should have minimal interaction with each other, except through asynchronous event and message passing on a shared message bus. Each service should have its own dedicated resources and be fully self-sufficient. The goal is to ensure that every service can perform it’s real-time synchronous functions without direct dependency on other services. Synchronous coupling of services will compound failure rates and ruin performance.
The fine-grained nature of the individual core services makes it challenging to apply common business logic and unified views of the underlying data. The aggregation tier provides a solution to this problem. Complex APIs and data feeds can leverage multiple services to build composite resource views. Aggregation services should be written with failure in mind. On every opportunity, the aggregation service should allow partial results to be returned to help alleviate issues caused by failed or degraded services.
Following the example from before, an aggregation API could consolidate content and comments into a single resource call. While a failure of the publishing service might cause this aggregation API to fail, it should be designed to allow comments to be omitted from its results if the comments service is unavailable. Allowing aggregation services to handle failure on a case-by-case basis ensures that failures have the most narrow impact possible.
The aggregation tier also provides the mechanism for base-service evolution and replacement. As underlying services gain new capabilities or are replaced by newer services, the aggregation tier services can be updated to utilize these changes, while maintaining a compatible external interface.
The delivery and client tiers are where additional per-channel (omnichannel) and application specific logic can be handled. Systems in the delivery tier could be transformational, like HTML rendering, or provide routing, forward-proxy caching, and even enforcement of channel-specific security mechanisms.
Conclusion
The explicit and external nature of microservice communication flips the complexity of traditional system on its head. Careful selection and development of your microservice architecture communication patterns will have huge benefits for your team's productivity and your company's digital strategy. Considering the risks of compounding failure will guide you to better service definitions, built around clear capabilities. Lastly, utilizing a four-tier architecture can create clarity by defining where service coupling takes place while allowing for optimal failure tolerance on a case-by-case basis.